
Building Reliable Data Extractors Using Apify’s Crawlee (Python SDK) for Automated Web Unblocking – [Building GenAI Apps #11]
Learn with a practical project: build a ProductHunt.com daily-top-products data pipeline.

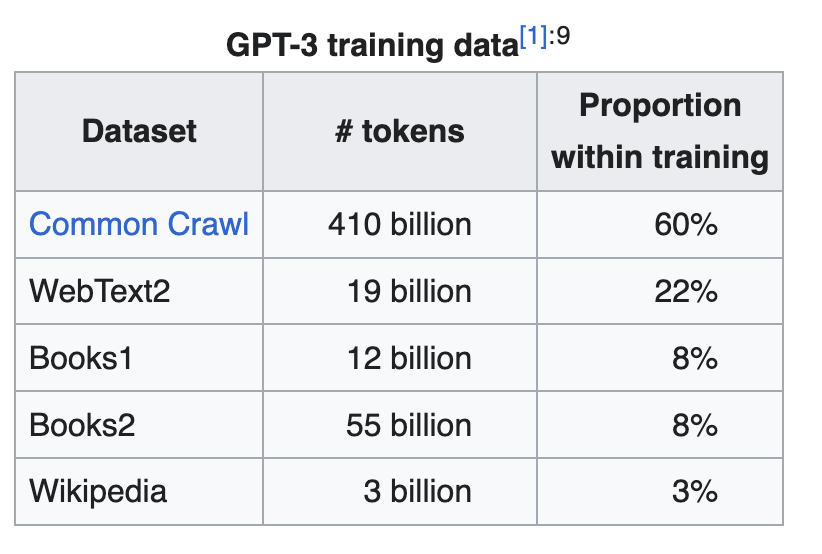
Artificial intelligence(AI) thrives on data, and the web continues to grow as a major source of data, projected to hold approximately 181 zettabytes of data by 2025. The significance of this resource is evident in models like GPT-3, where over 85% of its training data in 2020 was sourced from the public web, including datasets like Common Crawl, Wikipedia, and WebText2.
This wealth of web data fuels numerous AI innovations, such as boosting the ability of models like Claude to excel in coding tasks and more, drawing from high-quality, publicly available code repositories on platforms like GitHub.
Mastering web data extraction is essential to harness this vast potential, enabling the creation of robust datasets for training, fine-tuning, or analyzing trends in generative AI applications.
In this article, we will demystify web scraping, explore its challenges, and demonstrate how Apify’s Crawlee Python SDK provides a powerful, automated solution for reliable data extraction. Using ProductHunt.com as a practical example, I will guide you through building a data extractor to collect top daily startup tools listed on the platform.
Understanding Web Scraping: The Basics
Web scraping is the automated process of collecting publicly available information from websites by having a program script (often called a bot or crawler) load web pages, read their underlying HTML or API responses, and extract specific pieces of data such as product prices, article text, or images for analysis or reuse. Think of it as automating the process of extracting information from a webpage, such as product names or article headlines, but at scale and with precision.
Websites are built with:
HTML for structure,
CSS for styling, and often
JavaScript for dynamic content.
Scrapers use techniques like CSS selectors or XPath to navigate this structure. For example, a CSS selector like h3 targets all level-3 headings, while div.product-item might isolate product cards on an e-commerce site.
There are three main approaches to web scraping:
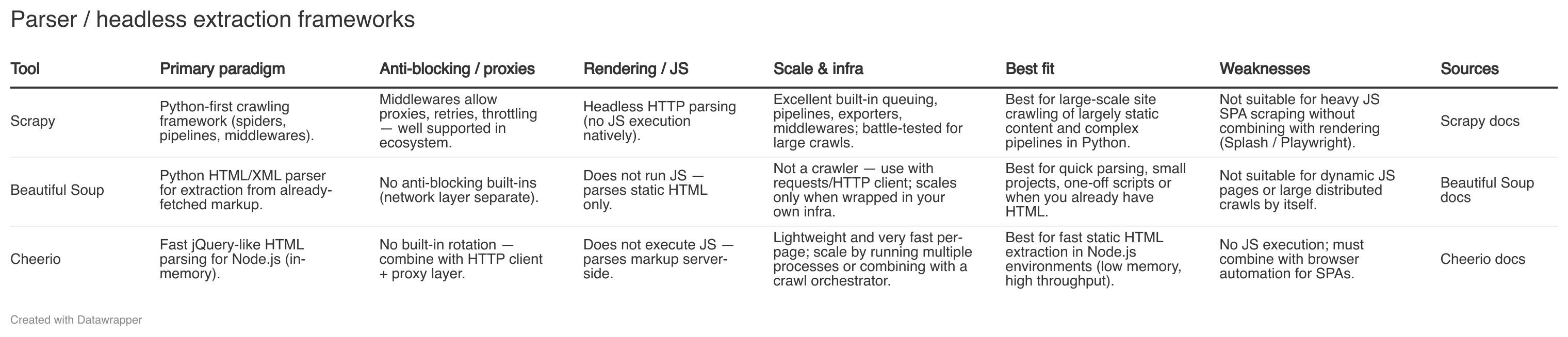
Static Scraping with CSS Selectors: Tools like BeautifulSoup parse raw HTML retrieved via HTTP requests. This is ideal for static websites where data is embedded in the HTML, such as extracting blog post titles and article content.
Dynamic Scraping with Browser Automation: JavaScript-heavy sites load content dynamically, requiring tools like Playwright or Selenium to render pages and mimic user interactions. This is crucial for platforms like public communities, where content appears after scrolling or clicking.
Network Capture via Internal APIs: Some websites fetch data through APIs, which can be intercepted to retrieve structured JSON data. This method requires identifying API endpoints using browser developer tools and is efficient for complex sites.
Each approach suits different scenarios, but all face challenges that we’ll address next.
Challenges of Web Scraping and Traditional Solutions
Web scraping is powerful but comes with legal and technical hurdles that must be navigated carefully to ensure reliable data collection.
Legal and Ethical Considerations
Scraping public websites is generally permissible, but must adhere to legal and ethical boundaries. Websites often specify acceptable behavior in their robots.txt file, which outlines rules for crawlers, such as which pages can be accessed. Respecting these rules and the site’s terms of service (ToS) is critical to avoid legal issues. Excessive requests can also overload servers, causing harm to the website.
Ethical scraping involves limiting request frequency, respecting ToS, and ensuring responsible use of data, especially when handling sensitive information.
Technical Challenges and Traditional Solutions
Technical obstacles often arise from anti-bot mechanisms designed to detect and block scrapers. These include:
IP Blocking: Websites block IPs sending excessive requests. Traditional solutions use Proxies to rotate IP addresses to distribute requests and mimic human traffic.
User-Agent Detection: Sites check the user-agent string to identify bots. Spoofing user-agents to resemble browsers like Chrome is a common countermeasure.
CAPTCHAs: CAPTCHAs challenge bots with puzzles or image recognition. Traditional solutions use AI-based or manual CAPTCHA solvers that attempt to bypass these whenever these challenges are detected.
Dynamic Content: JavaScript-driven sites require browser automation tools like Playwright to render content fully.
Rate Limiting: Websites restrict request frequency, necessitating delays or throttling in scrapers.
Traditional solutions like manual/ scheduled proxy rotation and user-agent spoofing often struggle against advanced anti-bot systems, which analyze behavioral patterns like request timing or mouse movements. This ongoing tug-of-war demands more sophisticated tools.
Web Unblocking: A Modern Solution
Companies like Apify, Bright Data, and Nimble leverage automation and AI to overcome these challenges, using techniques like browser fingerprinting to simulate human-like interactions.
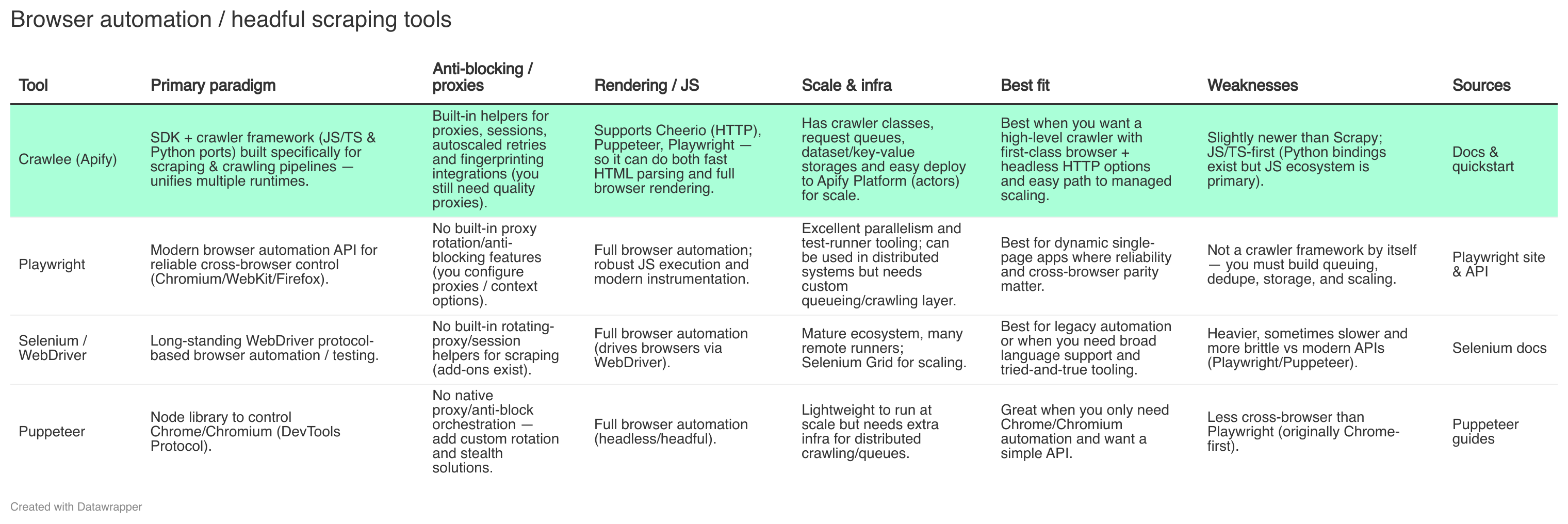
Browser fingerprinting involves generating realistic browser attributes such as screen resolution, headers, or plugins to make scraping requests indistinguishable from human traffic. This “web unblocking” approach ensures high success rates against anti-bot protections. Apify’s Crawlee, an open-source library, integrates these capabilities into a user-friendly SDK, automating proxy rotation, fingerprinting, and error handling to streamline data extraction.
Apify and Crawlee: Simplifying Data Collection
Apify is a comprehensive platform for web scraping and automation, centered around Actors—serverless micro-apps that encapsulate scraping logic, manage compute resources, and store data in structured formats.
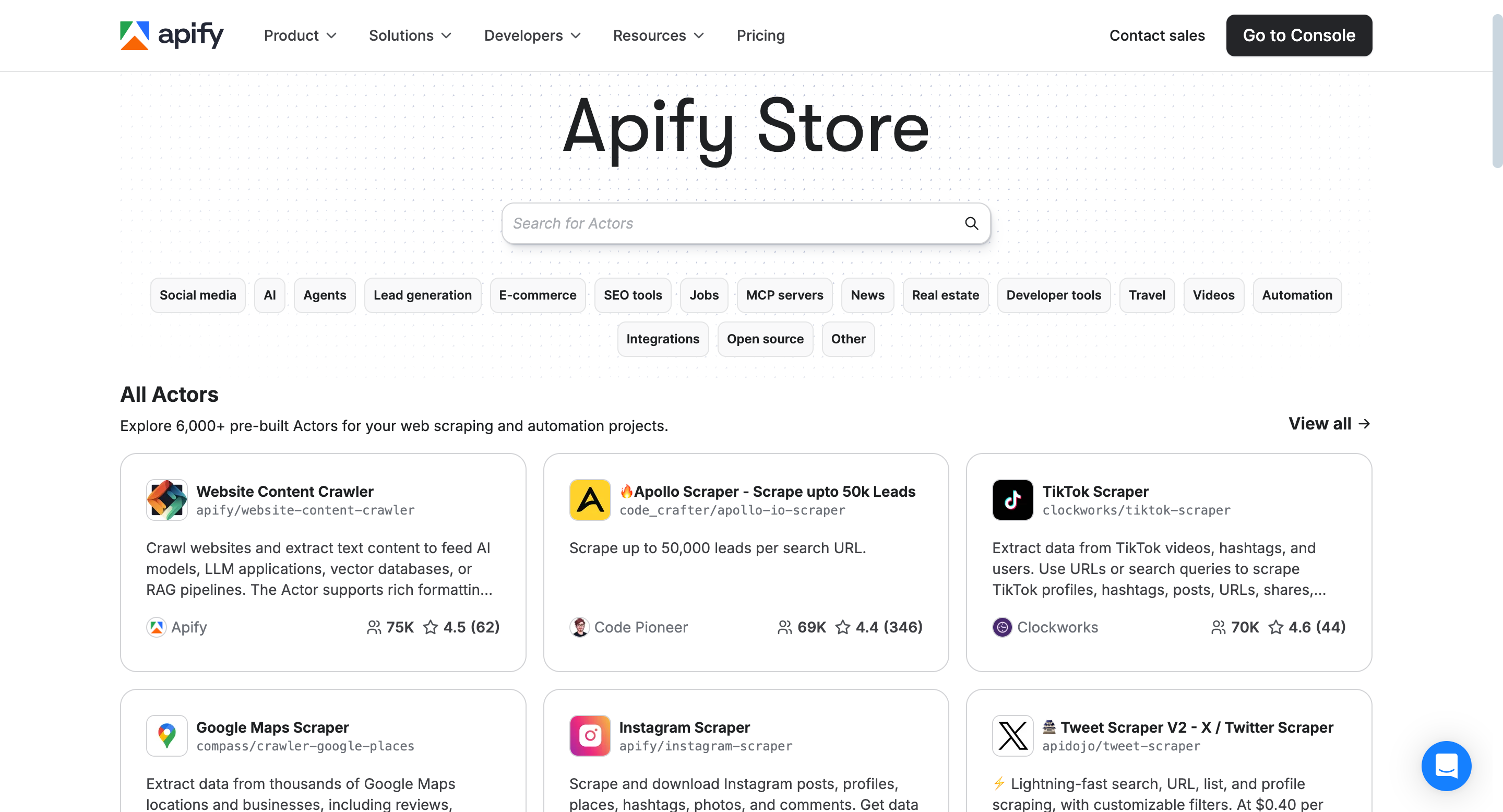
The Apify Store, a marketplace with over 6,000 pre-built Actors, enables developers to share or monetize their solutions. Crawlee, Apify’s open-source library, enhances these capabilities with features like:
Multiple Crawler Types: Support for
BeautifulSoupCrawler(static HTML),PlaywrightCrawler(dynamic content), andParselCrawler(XPath-based extraction).Automatic Scaling: Uses Python’s
asynciofor concurrent requests, optimizing performance.Proxy Management: Rotates proxies intelligently, discarding failures to ensure uninterrupted scraping.
Data Storage: Saves data to JSON or CSV files in a
storage/datasetsdirectory, with cloud storage options via Apify.Human-Like Behavior: Incorporates fingerprinting and retry mechanisms to bypass anti-bot defenses.
These features make Crawlee ideal for building reliable data extractors, particularly for AI applications requiring large-scale, diverse datasets.
Hands-On Tutorial: Building a ProductHunt Data Extractor
To get started with Crawlee and see it in action, let’s build an Actor to scrape ProductHunt.com, a platform that showcases innovative startup tools daily. Our goal is to extract details of top daily products, including names, descriptions, vote counts, and URLs, for use in market analysis or AI training.
Prerequisites
Before starting, make sure you have:
1. Python 3.10+ installed (`python --version` to check).
2. uv package manager (`pip install uv`) for fast dependency management.
4. Basic familiarity with
- Terminal/command-line usage
- HTML & CSS selectors (e.g., `div.product-card, body, span, h3`)
- Git (if you will be cloning the example repo)
Setting Up the Project
We’ll use Crawlee’s Python SDK with Playwright for dynamic scraping, as ProductHunt relies on JavaScript. Follow these steps:
Install a Package Manager: Use uv for efficient dependency management:
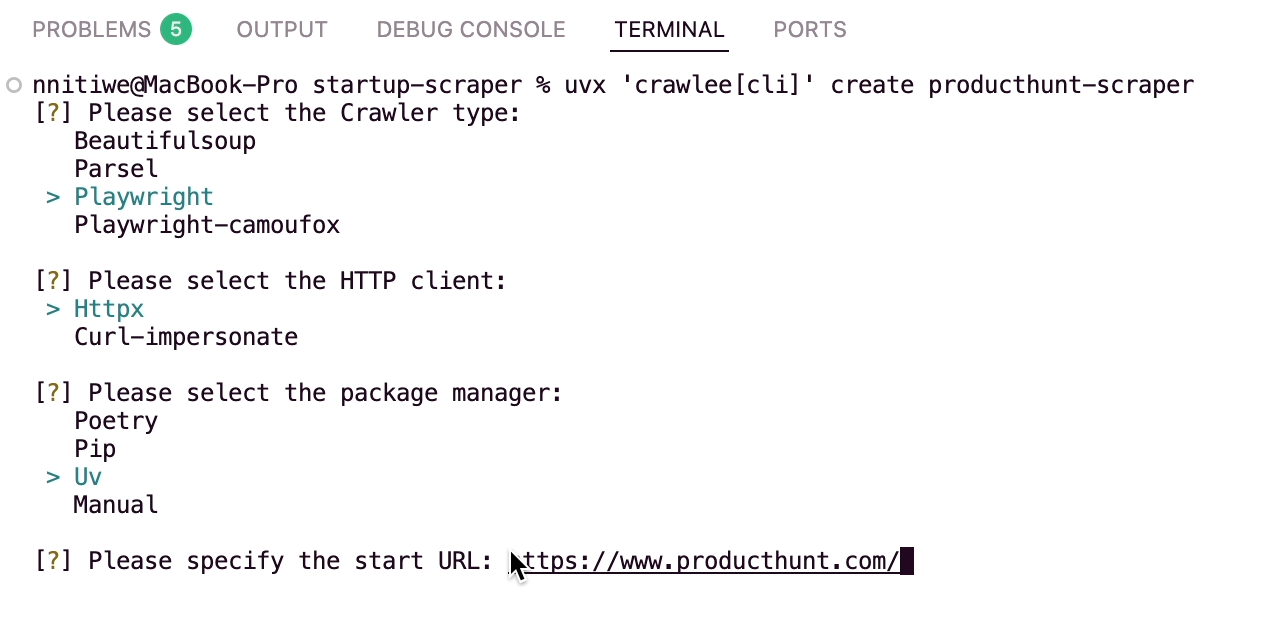
pip install uvCreate a Crawlee Project: Scaffold a project with Crawlee’s CLI:
uvx 'crawlee[cli]' create producthunt-scraperSelect:
Crawler Type: Playwright
HTTP Client: Httpx
Start URL: https://www.producthunt.com/
This creates a producthunt-scraper directory:
producthunt-scraper ├── Dockerfile ├── README.md ├── producthunt_scraper │ ├── __init__.py │ ├── __main__.py │ ├── main.py │ └── routes.py ├── pyproject.toml └── uv.lockProject Structure Overview: The routes.py file defines the scraping logic. Its default code includes a handler that logs the URL, extracts the page title, saves it to a dataset, and enqueues links for further crawling. We’ll modify this to target ProductHunt’s product listings.
Implementing the Scraper
Replace routes.py with the following code to scrape product details:
from crawlee.crawlers import PlaywrightCrawlingContext
from crawlee.router import Router
router = Router[PlaywrightCrawlingContext]()
@router.default_handler
async def default_handler(context: PlaywrightCrawlingContext) -> None:
"""Default request handler."""
context.log.info(f'Processing {context.request.url} ...')
title = await context.page.query_selector('title')
await context.push_data(
{
'url': context.request.loaded_url,
'title': await title.inner_text() if title else None,
}
)
await context.enqueue_links()Replace with the data extraction logic for ProductHunt.com:
from crawlee.crawlers import PlaywrightCrawlingContext
from crawlee.router import Router
from datetime import datetime
router = Router[PlaywrightCrawlingContext]()
@router.default_handler
async def default_handler(context: PlaywrightCrawlingContext) -> None:
"""Main handler for scraping Product Hunt products."""
context.log.info(f'Processing {context.request.url} ...')
page = context.page
products = []
# Wait for the page to load completely
await page.wait_for_load_state('networkidle')
# Wait for product cards to be visible
try:
await page.wait_for_selector('[data-test="homepage-section-0"]', timeout=10000)
except:
print("Could not find main product section, trying alternative selectors...")
# Find all product elements using Playwright selectors
product_elements = await page.query_selector_all('div[data-test*="post-item"], .styles_item__Dk_nz, [data-test*="post"]')
if not product_elements:
# Fallback selectors
product_elements = await page.query_selector_all('div:has(h3), article, .post-item')
print(f"Found {len(product_elements)} product elements")
# Process each product element
for index, element in enumerate(product_elements):
try:
# Get product name
name_element = await element.query_selector('h3, [data-test*="post-name"], a strong, strong')
name = await name_element.inner_text() if name_element else None
# Get product description
desc_element = await element.query_selector('p, [data-test*="post-description"], .description')
description = await desc_element.inner_text() if desc_element else None
# Get vote count
vote_element = await element.query_selector('[data-test*="vote-button"], button span, .vote-count')
votes = None
if vote_element:
vote_text = await vote_element.inner_text()
vote_match = vote_text.strip()
if vote_match.isdigit():
votes = int(vote_match)
else:
# Extract number from text like "123 votes"
import re
vote_nums = re.findall(r'\d+', vote_match)
if vote_nums:
votes = int(vote_nums[0])
# Get product URL/link
link_element = await element.query_selector('a[href*="/posts/"], a[href*="producthunt.com/posts/"]')
product_url = None
if link_element:
href = await link_element.get_attribute('href')
if href:
product_url = href if href.startswith('http') else f'https://www.producthunt.com{href}'
# Get maker/creator info
maker_element = await element.query_selector('[data-test*="maker"], .maker, .author')
maker = await maker_element.inner_text() if maker_element else None
# Get product image/logo
img_element = await element.query_selector('img')
image_url = await img_element.get_attribute('src') if img_element else None
# Only push data if we have a valid product name
if name and name.strip():
await context.push_data({
'scraped_url': context.request.loaded_url,
'scraped_at': datetime.now().isoformat(),
'rank': index + 1,
'name': name.strip(),
'description': description.strip() if description else None,
'votes': votes,
'product_url': product_url,
'maker': maker.strip() if maker else None,
'image_url': image_url
})
# Log progress
print(f"{index + 1}. {name.strip()} - {votes if votes else 'N/A'} votes")
products.append({
'rank': index + 1,
'name': name.strip(),
'votes': votes
})
except Exception as e:
print(f"Error processing product element {index + 1}: {e}")
continueCode Explanation
This code customizes the default handler to scrape ProductHunt’s product listings:
Imports and Setup: Imports
PlaywrightCrawlingContext,Router, anddatetimefor timestamping. The router directs requests to the handler.Page Loading: Uses
wait_for_load_state('networkidle')to ensure dynamic content is fully loaded.Selector Strategy: Targets product cards with multiple selectors (
[data-test*="post-item"],.styles_item__Dk_nz) and fallbacks (div:has(h3), article) for robustness against website changes.Data Extraction: Extracts product name, description, vote count, URL, maker, and image URL, handling edge cases (e.g., parsing votes with regex).
Data Storage: Saves valid products to a dataset with fields like scraped_url and scraped_at. Errors are logged to ensure the scraper continues running.
Logging: Prints progress to the console for debugging.
Running the Scraper
Execute the scraper with:
uv run python -m producthunt_scraperCrawlee processes the ProductHunt homepage, saving data to storage/datasets/default as JSON files (e.g., 000000001.json):
{
"scraped_url": "https://www.producthunt.com/",
"scraped_at": "2025-09-18T14:15:00.123456",
"rank": 1,
"name": "Your Next Store",
"description": "E-commerce platform for startups",
"votes": 344,
"product_url": "https://www.producthunt.com/posts/your-next-store",
"maker": "Startup Team",
"image_url": "https://ph-files.imgix.net/7e2b1515-6f4e-45b9-b87d-ba80670ef45a.png?auto=compress"
}The updated project structure includes:
producthunt-scraper
├── Dockerfile
├── README.md
├── producthunt_scraper
│ ├── __init__.py
│ ├── __main__.py
│ ├── __pycache__
│ │ ...
│ ├── main.py
│ └── routes.py
├── pyproject.toml
├── storage. 🆕
│ ├── datasets
│ │ └── default
│ │ ├── 000000001.json
│ │ ├── 000000002.json
│ │ ...
│ │ ├── 000000039.json
│ │ └── __metadata__.json
│ ├── key_value_stores 🆕
│ │ └── default
│ │ └── __metadata__.json
│ └── request_queues 🆕
│ └── default
│ ├── WlDxzkIrpBNBz6D.json
│ └── __metadata__.json
└── uv.lockTo explore this tutorial further and run it in your local environment, you can find the complete code on GitHub or visit Crawlee to explore advanced features.
Conclusion
Web data extraction is a cornerstone of generative AI, providing the raw material for training and fine-tuning models. Apify’s Crawlee Python SDK simplifies this process with robust automation, making it accessible to beginners and powerful for experts.
Our ProductHunt scraper demonstrates how to collect structured data efficiently, paving the way for applications in market analysis or AI development. In future articles, we’ll explore monetizing such extractors as Actors on the Apify Store, turning your scraping expertise into a scalable, revenue-generating solution.