
Model Inference as a Service: Accelerating AI Deployment with Serverless GPU Compute (Image-to-Video Example)
How to get fast, reliable AI inferences without huge hardware bills

According to Gartner’s 2024 report, “10 Best Practices for Optimizing Generative AI Costs,” a key prediction warns that through 2028, more than 50% of generative AI projects will exceed their budgets due to inadequate architecture and a lack of operational expertise.
Scenario: You are a startup founder on a mission to create an AI-powered photo or video editing platform.
How can you achieve this in the fastest and most cost-effective way?
A few years ago, this would’ve meant wrangling GPUs on AWS, configuring servers, and spending weeks on setup. Today, you can achieve it in minutes with a few lines of code, thanks to model inference as a service (MIaaS). This is the power of modern AI APIs—tools like Claude or OpenAI’s GPT series have abstracted away the complexities of model deployment, cloud orchestration, scaling, and maintenance.
Where startups and small businesses once needed entire teams to manage these tasks, anyone can now tap into sophisticated AI with simple API calls, paying only for the data processed or generated, often via token-based pricing. This shift has made generative AI accessible, but it also raises a question:
How do you efficiently serve complex models, such as those for image-to-video generation, without getting bogged down by infrastructure?
In this article, part of the “Building GenAI” series, we’ll explore model inference as a service—a cloud-based approach that streamlines deploying and running AI models. We’ll break down what inference is, why it matters, and the challenges of traditional self-hosted approaches. Then, we’ll dive into how MIaaS, powered by serverless GPU compute, transforms the process, using a practical image-to-video example with a platform like Novita AI to show how developers and businesses can get started.
What Is Model Inference and Why Does It Matter?
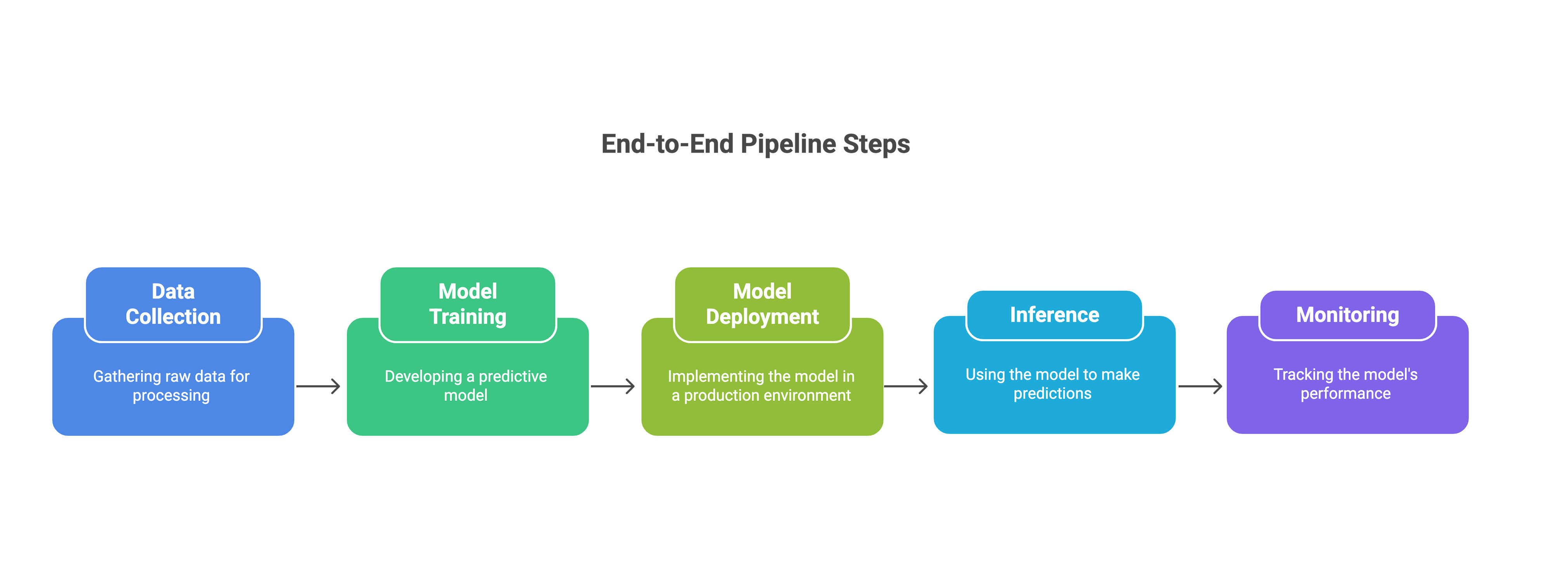
Model inference is the process of using a trained AI model to make predictions or generate outputs from new data. For traditional machine learning, this might mean loading a scikit-learn model (serialized as a joblib or pickle file) to predict customer churn.
In generative AI, it’s more complex—think running a model like DeepSeek for text generation or Flux for image creation. These models, often billions of parameters large, demand significant compute power, typically GPUs, to process inputs efficiently.
Inference is the bridge between a trained AI model and real-world applications, whether it’s generating a video, answering queries, or creating audio.
For businesses and developers, efficient inference is critical. It determines how fast, reliable, and cost-effective your AI application is. But deploying inference pipelines traditionally is no small feat, especially for generative models requiring specialized hardware and optimization to handle real-time or batch requests.
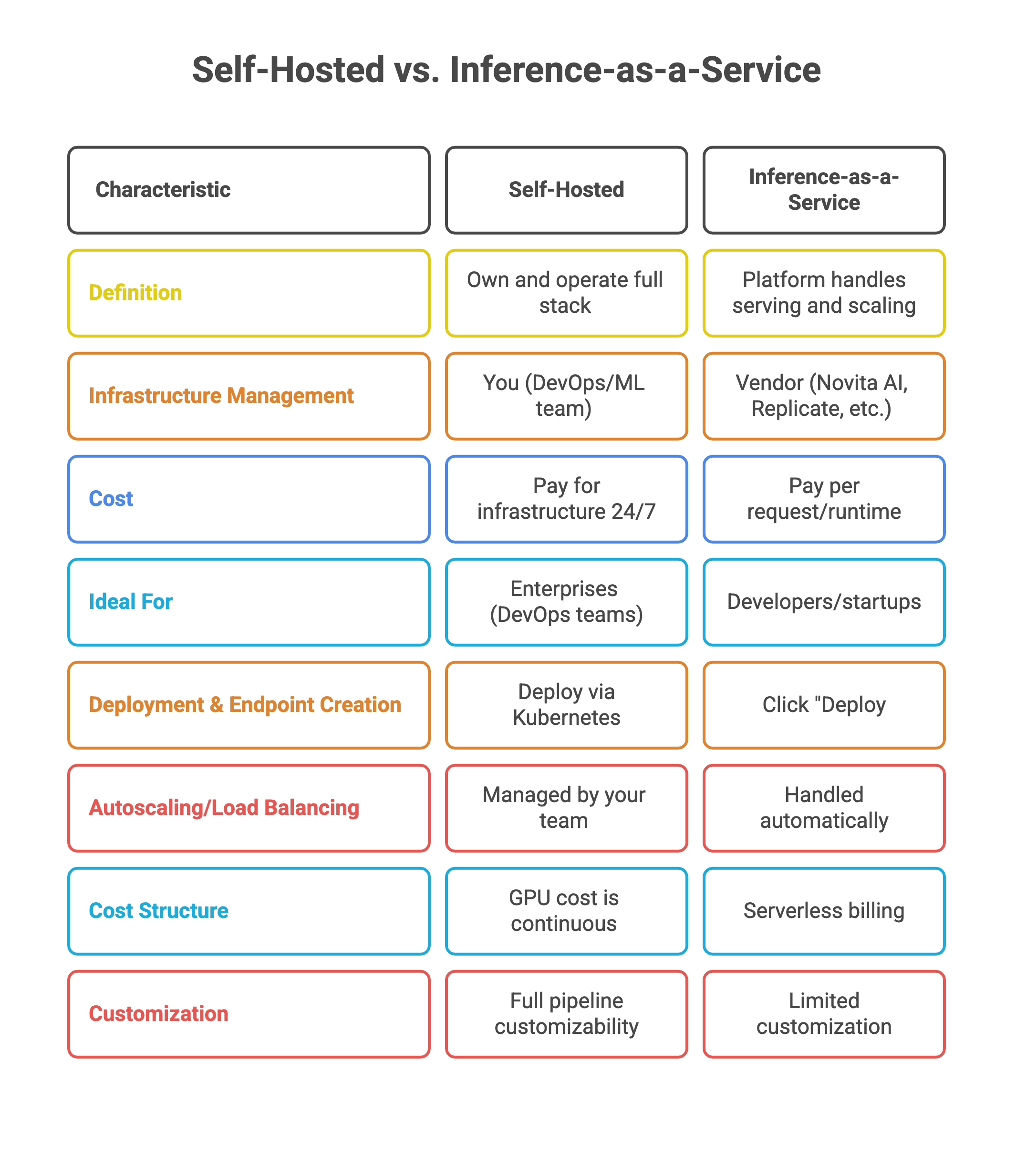
This is where the choice between self-hosted and inference-as-a-service solutions becomes pivotal.
Challenges of Self-Hosted Model Inference
Running your own inference setup sounds empowering, but it comes with steep challenges that can hinder speed, cost, and efficiency, particularly for resource-constrained teams.
Let’s unpack the key issues.
Complexity of Infrastructure Management:
Deploying a model like Seedance or LLaMA requires provisioning GPUs, configuring server clusters, and optimizing resource consumption. Developers need expertise in hardware selection, cloud platforms, and cost management to avoid overpaying for underutilized resources.
For instance, setting up a Kubernetes cluster to handle model serving involves defining resource limits, managing node pools, and ensuring fault tolerance—a steep learning curve for non-specialists.
Scalability:
Demand for AI applications can be unpredictable, spiking during peak usage or dropping to near-zero. Self-hosted setups require manual scaling logic, along with autoscaling policies, load balancers, and failover mechanisms to handle it. Misjudge the configuration, and you risk downtime or over-provisioned servers racking up costs.
The “hidden tax” of cluster management, including monitoring, logging, and tweaking configurations, takes time away from improving models or building features.
Billing Strategy:
Self-hosted setups often involve renting servers or GPUs 24/7, even when idle. Unlike serverless models, which charge only for compute used, self-hosted inference locks you into fixed costs, making it hard to align expenses with the actual workload.
For startups or SMEs, this can strain budgets, especially when experimenting with multiple models.
Deployment Speed:
Building an inference pipeline from scratch—data preprocessing, model loading, and request routing takes time. Every component needs testing, and integrating them into a production-ready system can stretch weeks. In the fast-paced GenAI space, this delay can mean falling behind competitors who leverage faster solutions.
Model Inference as a Service: A Streamlined Alternative
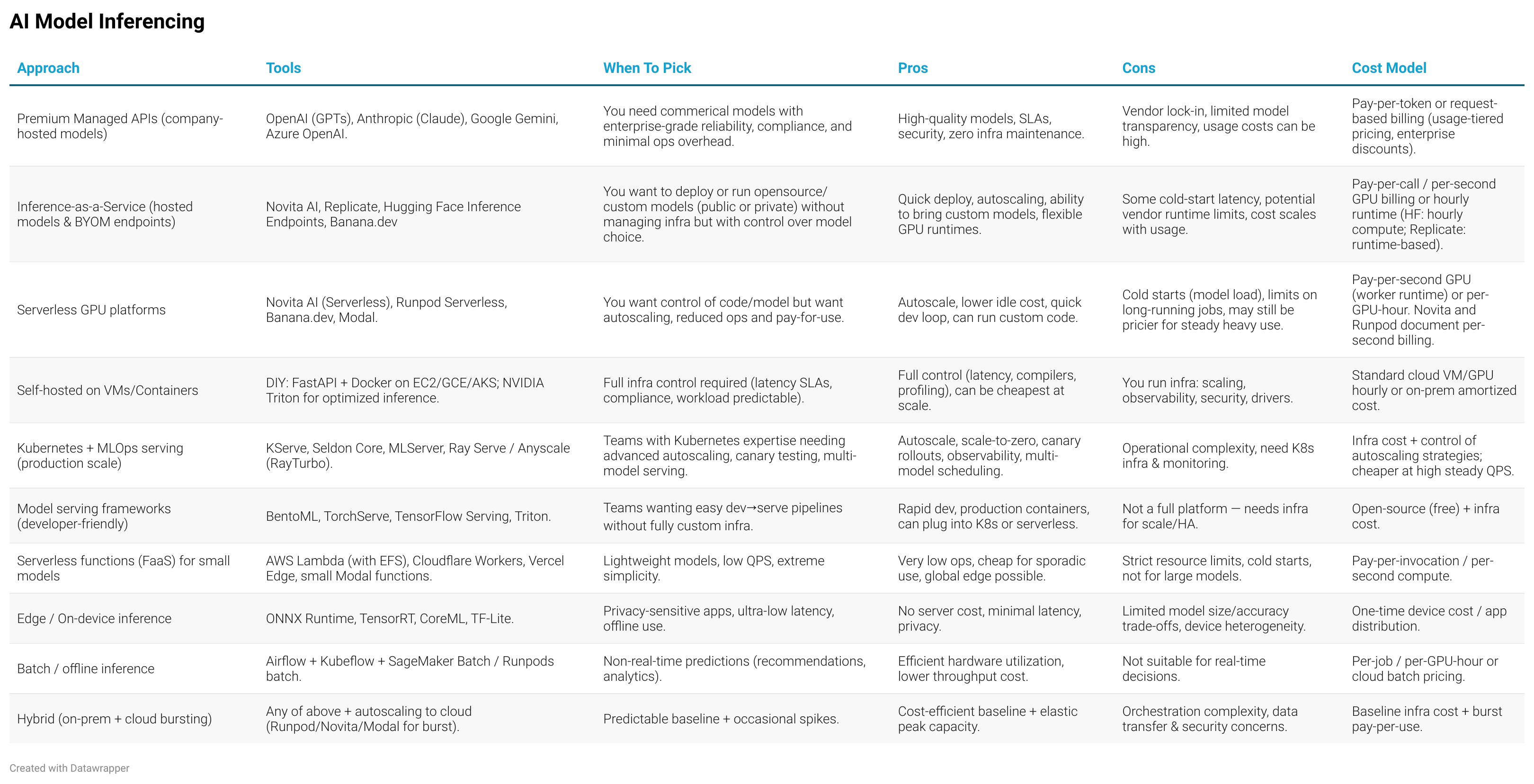
Model inference as a service (MIaaS) offers a way to bypass these challenges. In essence, MIaaS lets you deploy and run AI models in the cloud without managing hardware or infrastructure. You upload a model (or use a pre-hosted one), send data via an API, and get results back.
It’s like renting AI compute power on demand, similar to calling an Uber rideshare instead of maintaining your own car. This is especially valuable for generative models, which are resource-hungry and complex to scale.
How MIaaS Works
With MIaaS, the cloud provider handles the heavy lifting: hosting models, managing GPUs, and scaling resources. You interact through APIs, sending inputs (like text prompts or images) and receiving outputs (like generated videos or text).
For example, platforms like Novita AI offer access to over 200 open-source models for tasks like text generation (KIMI, Qwen), image creation, or video synthesis (Seedance). The service manages container orchestration, often using tools like Kubernetes under the hood, so you don’t need to.
Key Benefits of MIaaS
The advantages of MIaaS are transformative, especially for developers and businesses looking to move fast.
Automatic scaling means the platform adjusts GPU resources to match demand, handling thousands of concurrent requests or scaling to zero when idle. This eliminates the need to code scaling logic or monitor clusters.
Novita AI, for instance, uses serverless GPU compute to spin up resources only when needed, ensuring efficiency.
Cost optimization is a major draw. With pay-per-use billing, you’re charged only for the milliseconds of GPU time consumed—no idle costs. This contrasts with renting servers outright, where you pay regardless of usage.
Novita advertises up to 50% cost savings compared to self-hosted setups, making it easier to experiment without breaking the bank.
Operational excellence comes built-in. MIaaS platforms handle patching, driver updates, and reliability, freeing you to focus on model development or application logic. Deployment is rapid too—new models can go from code to live API in minutes, unlike the weeks needed for custom pipelines.
Novita’s template libraries (e.g., pre-configured environments for LLaMA-Factory or ComfyUI) simplify custom deployments, while integrations with Hugging Face let you pull models seamlessly.
Flexible Features for Developers
The Novita MIaaS platform offers a range of tools to suit different needs:
You can access inference APIs for pre-hosted models, covering text, audio, image, and video tasks.
If you have a custom model, serverless GPU instances let you deploy it with automatic scaling and pay-as-you-go pricing.
For more control, reserved GPU instances (like A100 or RTX 4090) provide dedicated resources with global distribution for low latency.

These options make MIaaS versatile, whether you’re prototyping a new idea or scaling a production app.
A Practical Example: Image-to-Video with Seedance V1 Lite
Suppose you want to generate a short video from an image, say a cartoon character performing a moonwalk on stage. Using a model like Seedance V1 Lite, which excels at coherent multi-shot video generation with smooth motion, you can achieve this without managing any infrastructure.
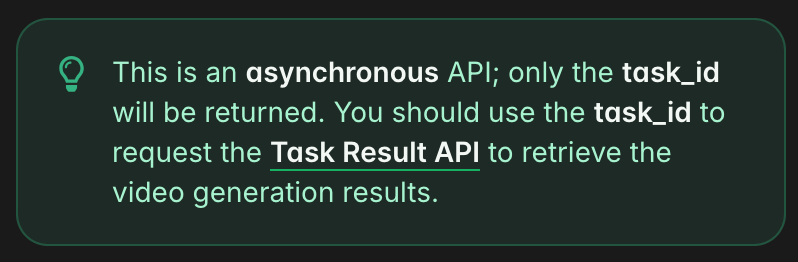
The Seedance V1 Lite model, hosted on Novita AI, supports resolutions up to 1080p and is accessed via an asynchronous API.
Let’s walk through the steps using Python.
STEP 1: Signup & Generate API Key
Sign up on a platform like Novita AI to get an API key, which authenticates your requests.
STEP 2: Install Dependencies
Next, set up your Python environment. You’ll need libraries like requests for API calls and python-dotenv to manage your key securely.
Create a requirements.txt:
requests
python-dotenvThen, add a .env file with:
NOVITA_API_KEY=your_api_key_hereSTEP 3: Write Python Scripts
Now, write a script (image_to_video_generator.py) to call the API endpoint https://api.novita.ai/v3/async/seedance-v1-lite-i2v. The payload includes your prompt, an input image (via URL or base64-encoded file), resolution, and parameters like duration or seed for consistency:
from dotenv import load_dotenv
import os
import requests
import base64
load_dotenv()
url = “https://api.novita.ai/v3/async/seedance-v1-lite-i2v”
image_url = “https://img.freepik.com/premium-vector/presenting-black-male-teacher-presenter-82_905719-2960.jpg”
api_key = os.getenv(”NOVITA_API_KEY”)
def generate_video(prompt, image=image_url, resolution=”720p”, aspect_ratio=”16:9”, camera_fixed=False, seed=123, duration=5):
try:
payload = {
“prompt”: prompt,
“image”: image,
“resolution”: resolution,
“aspect_ratio”: aspect_ratio,
“camera_fixed”: camera_fixed,
“seed”: seed,
“duration”: duration
}
headers = {
“Content-Type”: “application/json”,
“Authorization”: f”Bearer {api_key}”
}
response = requests.post(url, json=payload, headers=headers)
return response.json()
except Exception as e:
print(f”Error: {e}”)
return NoneThis returns a task_id since the process is asynchronous.
To fetch the video, poll the endpoint https://api.novita.ai/v3/async/task-result with a script like save_generated_video.py:
import requests
import os
import time
import itertools
import sys
from dotenv import load_dotenv
load_dotenv()
url = “https://api.novita.ai/v3/async/task-result”
sys.stdout.reconfigure(line_buffering=True)
os.environ[”PYTHONUNBUFFERED”] = “1”
api_key = os.getenv(”NOVITA_API_KEY”)
OUTPUT_DIR = “output”
os.makedirs(OUTPUT_DIR, exist_ok=True)
def download_file(file_url, filename):
try:
response = requests.get(file_url, stream=True)
response.raise_for_status()
file_path = os.path.join(OUTPUT_DIR, filename)
with open(file_path, “wb”) as f:
for chunk in response.iter_content(chunk_size=8192):
f.write(chunk)
print(f”\n✅ Saved: {file_path}”)
except Exception as e:
print(f”\n❌ Download failed: {e}”)
def get_task_result(task_id, poll_interval=10):
spinner = itertools.cycle([”|”, “/”, “-”, “\\”])
while True:
try:
params = {”task_id”: task_id}
headers = {”Authorization”: f”Bearer {api_key}”}
response = requests.get(url, headers=headers, params=params)
result = response.json()
if “task” not in result:
print(f”\n❌ Invalid response: {result}”)
return None
status = result[”task”].get(”status”)
sys.stdout.write(f”\rChecking task status {next(spinner)} [{status}]”)
sys.stdout.flush()
if status == “TASK_STATUS_SUCCEED”:
print(”\n✅ Task completed!”)
for i, v in enumerate(result.get(”videos”, []), start=1):
video_url = v.get(”video_url”)
if video_url:
download_file(video_url, f”video_{i}.mp4”)
print(”✅ All files saved to /output/”)
break
elif status in [”TASK_STATUS_PROCESSING”, “TASK_STATUS_QUEUED”]:
pass
else:
print(”\n❌ Task failed.”)
break
time.sleep(poll_interval)
except KeyboardInterrupt:
print(”\n🛑 Stopped by user.”)
break
except Exception as e:
print(f”\n❌ Error: {e}”)
breakTie it together in main.py:
from image_to_video_generator import generate_video
from save_generated_video import get_task_result
if __name__ == “__main__”:
task_result = generate_video(prompt=”make a video of the cartoon man doing a moonwalk dance on stage (in full view, head to toe showing).”)
if task_result and “task_id” in task_result:
print(”Task ID:”, task_result[”task_id”])
get_task_result(task_result[”task_id”])STEP 4: Results
Run python main.py, and your video will land in the output folder after processing.
This example shows how MIaaS removes the need to manage GPUs or scaling, letting you focus on creative prompts and results.
Why MIaaS Matters for Businesses and Developers
For businesses, MIaaS lowers the barrier to adopting AI. Instead of investing in hardware or hiring infrastructure experts, you can integrate AI features via APIs, paying only for what you use. This is ideal for SMEs looking to add capabilities like video generation or customer support chatbots without ballooning costs. Developers benefit from the speed and flexibility—prototyping becomes a matter of tweaking prompts or models, not wrestling with servers. The image-to-video example above shows how quickly you can go from idea to output, a process that would’ve taken weeks in a self-hosted setup.
As you dive into model inference, platforms like Novita AI offer a gateway to explore these possibilities. Whether you’re building a creative tool, automating workflows, or scaling a business application, MIaaS provides the tools to move fast and stay lean.
Try experimenting with different models or prompts to see what’s possible—your next project might be just an API call away.
This piece really made me think. This 'Building GenAI' series always gives such good perspective.